|
Ashmal Vayani I am an MSc. student in the College of Engineering and Computer Science department at the University of Central Florida. I am a member of the Center for Research in Computer Vision (CRCV) Lab advised by Prof. Mubarak Shah. I am currently also working as a Research Engineer at Subquadratic, working on long-context learning and building efficient architectures to reduce the quadratic complexity of large language models.
Previously, I was a Research Engineer in the Computer Vision Department, affiliated with the IVAL-Lab at Mohamed bin Zayed University of Artificial Intelligence (MBZUAI).
I was advised by Prof. Fahad Khan, and Dr. Salman Khan (Aug 2023 - Jul 2024). During my undergrad, I worked as a Research Intern at Retrocausal with Dr. Zeeshan Zia. I completed my Bachelors from National University of Computer and Emerging Sciences , majoring in Computer Science (Aug 2019 - June 2023).
Email / CV / Google Scholar / Github / LinkedIn |

|
Research InterestsI mostly work on Large Language Models, Vision Language Models, Responsible AI, Privacy & Bias, their efficiency, and building downstream industrial applications using RAG methods and LLM deployment.I have also curated high-quality datasets and benchmarks for Multilingual LMMs, Bias Mitigation, and Industrial Applications for the MENA region. |
News |
Publicationsselected publications, full here * denotes joint first authors |
|
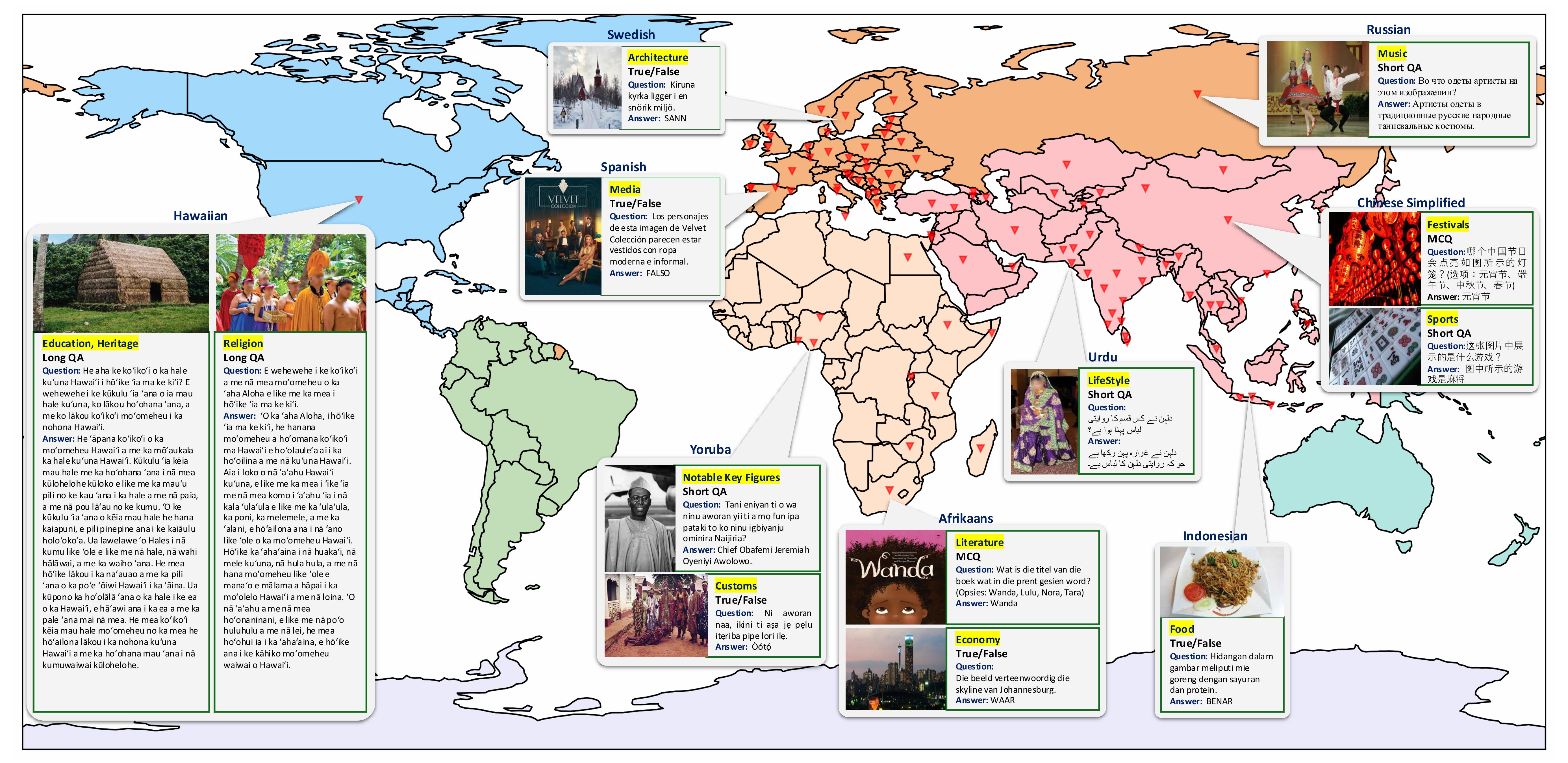
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Ashmal Vayani, Dinura Dissanayake, Hasindri Watawana, Omkar Thawakar, Michael Felsberg, Thamar Solorio, Monojit Choudhury, Ivan Laptev, Mubarak Shah, Salman Khan, Fahad Shahbaz Khan CVPR 2025 (Highlight) Paper / Project / Code / Data |
|
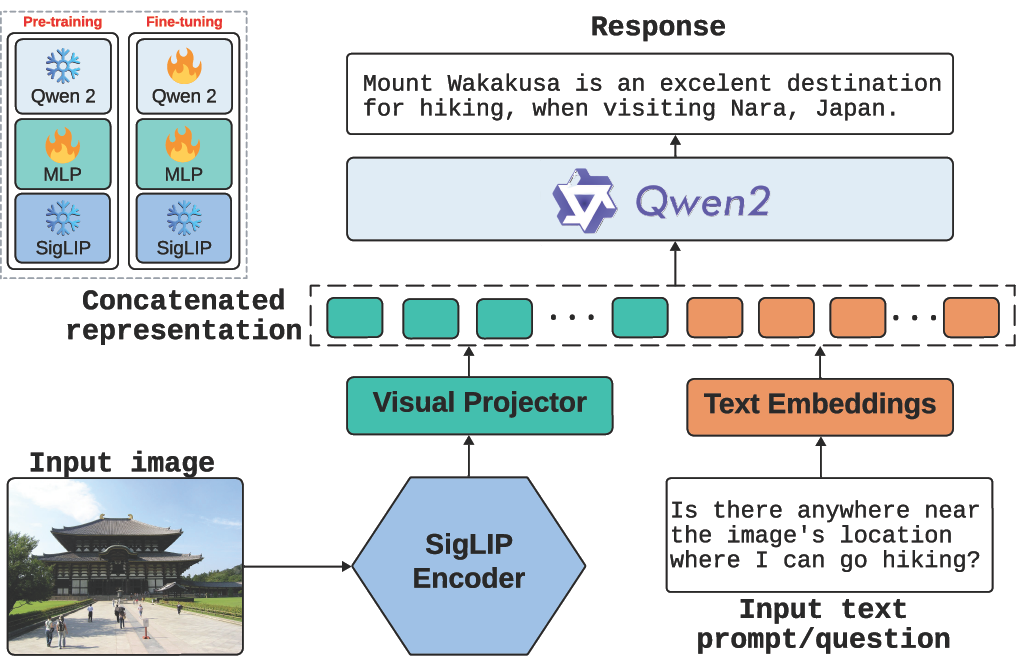
GAEA: A Geolocation Aware Conversational Assistant
Ron Campos*, Ashmal Vayani*, Parth Parag Kulkarni*, Rohit Gupta Aizan Zafar, Aritra Dutta, Mubarak Shah, WACV 2026 Paper / Project / Code / Data |

|
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Bhuiyan Sanjid Shafique, Ashmal Vayani, Muhammad Maaz, Hanoona Abdul Rasheed, Dinura Dissanayake Michael Felsberg, Mubarak Shah, Salman Khan Fahad Shahbaz Khan EMNLP 2025 (Main) Paper / Project / Code / Data |

|
Beyond Content: How Grammatical Gender Shapes Visual Representation in Text-to-Image Models
Muhammed Saeed, Shaina Raza, Ashmal Vayani, Muhammad Abdul-Mageed, Ali Emami, Shady Shehata EMNLP 2025 (Findings) Paper |

|
VURF: A General-purpose Reasoning and Self-refinement Framework for Video Understanding
Ashmal Vayani*, Ahmad Mahmood*, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan NeurIPS Vision Language Models Workshop 2024. Paper / Code |
|
MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT
Omkar Thawakar*, Ashmal Vayani*, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Michael Felsberg, Timothy Baldwin, Eric P. Xing, Fahad Shahbaz Khan ICLR SLLM Workshop 2025 (Spotight) Paper / Code / Models |
|
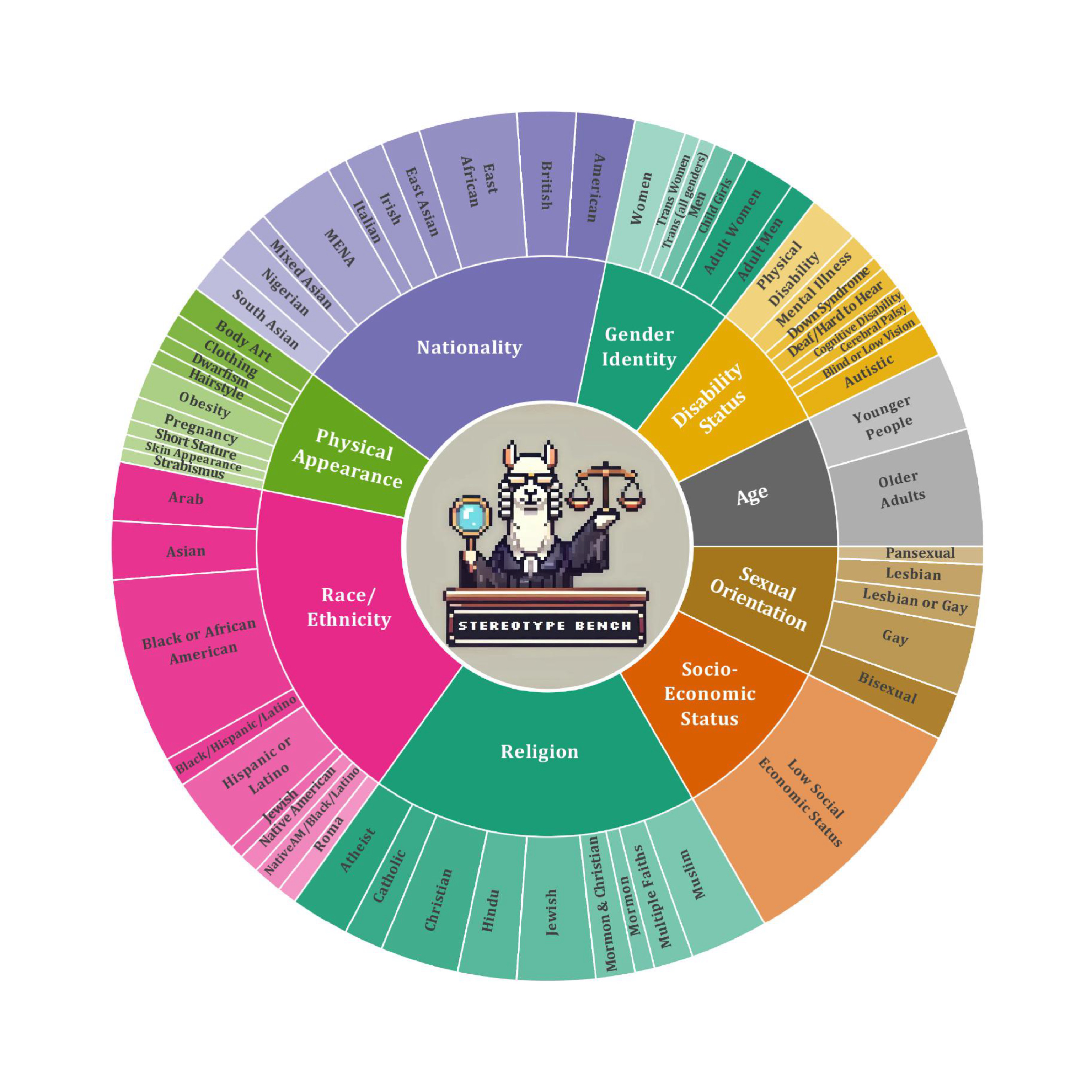
SB-Bench: Sstereotype Bias Benchmark for Large Multimodal Models
Vishal Narnaware*, Ashmal Vayani*, Rohit Gupta, Swetha Sirnam, Mubarak Shah Under Review Paper / Project / Code / Data |